
Analyzing URL Parameters with Python for SEO
Admittedly, it has been a while since I last spoke about Python at the 3XEDigital in Dublin and at BrightonSEO. But very often, I still find myself in the same situations as I discussed during my talk. One of the frequent challenges I mentioned in my talk involved analysing URL parameters in bulk.
As you know very well, tasks of this kind can be very time consuming and boring. Furthermore, going through thousands of rows of data is very prone to error.
Python to the rescue! In this article aiming at beginners, you will learn how to use Python to extract any URL parameter from a CSV file, count, sort and save them in a spreadsheet for further analysis. All in one go, quickly, efficiently and definitely not boring!
For the impatient or those who live the busy agency life, you can skip to the bottom of the article where a script ready to be copied and pasted is waiting for you. Just make sure to adjust the three top variables to your own needs and you are ready to go!
Prerequisites
The two commands below will install all packages needed for this script to run. We will not be making use of numpy directly, but it will need to be installed as a runtime dependency for pandas. Depending on your Python environment (especially looking at macOS users), you might need to change python to i.e. python3.8 instead.
Jump to the Further Reading section if you require some context around installing or upgrading Python on your OS.
python -m pip install pandas
python -m pip install numpyImportance of URL parameters for SEOs
Technically speaking, URL parameters consist of any number of queries and their values:
| https://www.example.com?query1=value1&query2=value2 |
A URL parameter alone does nothing, but is usually interpreted by the webserver to change the content of a page. They are also very popular to interact with APIs as this query and value combination can carry all information needed for a so called POST or GET request. However, in this article, we will be solely focusing on their use on e-commerce websites.
To remind ourselves why we are doing this here is a quick recap of why and when URL parameters matter in SEO:
- Pagination
- Filtering the number of products shown on an e-commerce website
- Filters for faceted navigation
- Tracking parameters i.e. appended by Google Analytics
- Internal search
Although URL parameters are often used to realise any of the smart features listed above, things can easily go very wrong. Those parameters can introduce, often without any warning, super large numbers of duplicate and low-value URLs. When talking about large e-commerce sites, I have witnessed how a single parameter on a Product Lister Page inflated the overall crawlable size of the site by 4 million URLs – that’s huge!
In order to aid search engines to find valuable URLs without any distraction, analysing URL parameters is an inevitable first step to take. Only then we are able to make data-led decisions on a quite granular URL level, involving the following steps:
- The URL is valuable and should be accessible to search engines
- The URL is of low value and should be blocked by robots.txt
- The URL parameter is not needed and should be removed from the URL/internal linking
Google’s Legacy URL Parameters tool
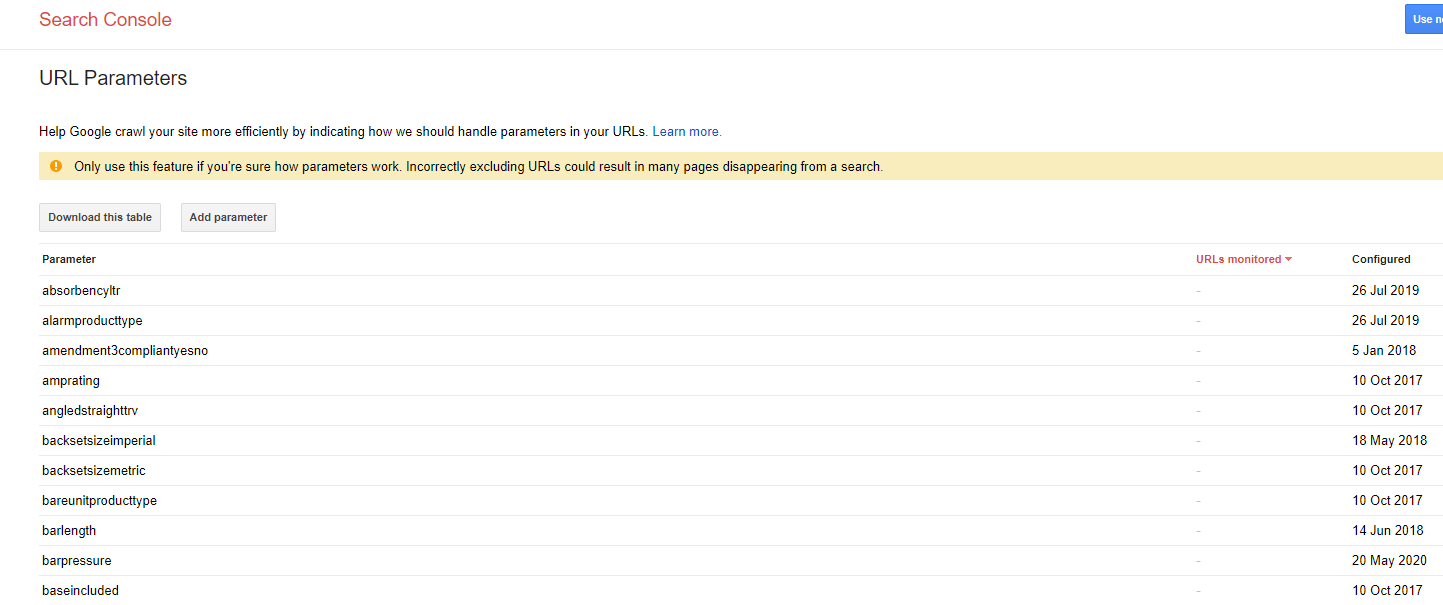
Google offers a tool to define the handling of URL parameters within Google Search Console. It allows specifying whether URLs containing a certain parameter should be crawled or not or what a parameter does to the displayed content.
Personally, I would try to avoid the use of this tool. Its settings only apply to GoogleBot and will not impact the crawling behaviour of other search engines such as Bing, Yandex, Ask, Duckduckgo and so on. If you rely on parameter handling for your site, I recommend making use of the robots.txt instead. It allows more control over which URLs to block or open and is understood by all search engines.
What I do like about this tool is that it is showing the number of URLs monitored. This is a great starting point to understand how many URLs contain a parameter to then make an informed decision about its crawl handling.
However, as you can see in the screenshot above as well, Google may decide to show no URLs at all – and even if they do, they may not be representative of the whole site at all. How great would it be if we could replicate the good parts of that view with actual crawl data with just a few lines of Python code? The good news is, we can! It is very straightforward – checkout the below.
In the beginning was the Input File
Before we jump into any coding, we need an export file that contains the URLs we want to report on. Of course, you can use any data source of your choice. In this example, we are using the output of a ScreamingFrog crawl. I suggest filtering the input file to URLs that resolve with a 200 OK status code only or are reported to be indexable.
Awesome! We are now ready to get our hands on some nifty Python code. Firstly, we should define two variables to tell our Python script where to look for the input file and where to save our output file.
input_file = "C:/Users/benjamin/crawls/crawl_export.csv"
output_file = "parameters.csv"We also only want to look-up a single column from our input CSV file that contains the URLs. We can ignore all other columns to ensure that we have a lightweight input that can be processed as efficiently as possible. In my case, ScreamingFrog stored the crawled URLs in the Address column.
url_column = "Address"Okay, now we need to read our input file so we can process it further with Python. We will be using the powerful pandas library which is, because of its versatility, incredibly popular among data scientists. However, for this scenario, we will mostly be using it for loading and saving our CSV data. Hence, we will only import a single class and function from it.
from pandas import DataFrame, read_csvThe function read_csv can now be used to load our CSV file. The usecols= parameter specifies the column we are interested in:
urls = read_csv(input_file, usecols=[url_column])[url_column].unique()As you can see, we just use read_csv to create a DataFrame to then immediately call the unique() function on the URL column which returns a numpy array. This step ensures we are not analysing any duplicated URLs and makes it easier to loop through it and process it afterwards.
Pandas is an incredibly useful library, but not all tasks need to be performed with it. For this particular task, we only need basic functions that can be all achieved with pure Python. In a time when I was overly obsessed with pandas, a veteran Python developer once looked at my code and advised me to only make use of pandas (or any other library) if it is really needed – it results in fewer dependencies and potentially cleaner and faster code. I did not want to hear it back then – but of course, he turned out to be right.
Parsing URL parameters
Ok, now our input data is ready for further processing and stored in the urls variable. But how do we extract the parameter from an URL? Fortunately, we can make use of one of the many great Python libraries – urllib. This library is optimised and well tested for this very purpose. The following imports load the functions we need:
import urllib.parse as urlparse
from urllib.parse import parse_qsExample URL with parameters
| https://www.example.com?query1=value1&query2=value2 |
urlparse will break our URL string into components such as
- scheme (i.e. http or https)
- netloc (i.e. example.com)
- path (ie. /my/folder)
- query (?filter1=value1&filter2=value2)
- etc.
We are only interested in query as it captures the URL part we are interested in. As query includes the whole parameter string including values, we need to process and segment it further. That is when parse_qs comes into play. Through it, we will be able to extract the parameters filter1 and filter2 only.
Algorithm to extract and count URL parameters
The idea of the algorithm is simple:
- Loop through all our imported URLs
- For each URL, extract the query string
- For each query string, extract the parameter
- Store each newly discovered parameter and count its occurrences
This is how the above algorithm can look like in Python – of course, there are many ways to achieve this.
parameters = {}
for url in urls:
query_string = urlparse.urlparse(url)
for param in parse_qs(query_string.query):
parameters[param] = parameters.get(param, 0) + 1So just a few lines of code do all the heavy work for us – beautiful, isn’t it?
But what is actually happening there? I decided to store each discovered parameter in a dictionary. Python dictionaries have a very low look-up time for keys which makes it a very performant choice. Instead of going for a defaultDict and assigning the default counter value to 0, I decided to use the .get() function which returns 0 should a key not exist. This allows us to increment the value of keys that did not exist before without having to add an if condition that checks for the existence of the parameter as a key.
The above code will take note of any parameter as a dictionary key and stores its occurrences as a dictionary value.
To get a hit list of parameters ordered by their number of occurrences, we need to sort the dictionary by its values, in descending order.
This can be easily achieved with the inbuilt sorted() function. We will define and pass on a single-line lambda function to it that only returns the value of each key in list format. The sorted function will then take care of the ordering. The parameter reverse=True tells the inbuilt function to order the values descendingly and not, as it would do per default, in ascending order.
Eventually, we use a list comprehension to iterate over the sorted keys and values to create a list of tuples [(key1, value1), (key2, value2)].
parameters = [(key, value) for key, value in sorted(parameters.items(),
key=lambda item: item[1], reverse=True)]As mentioned at the beginning, we only want to use Pandas for loading and saving the data. The created list of tuples makes it very easy to create a new DataFrame:
DataFrame(parameters, columns=["Parameter", "Count"]).to_csv(output_file, index=False)The single line of code above converts our list of tuples into a DataFrame, assigns two columns to each element in the tuple and finally disables the index. Otherwise, you would be getting a numbered index as an additional column.
And that’s it! With less than 20 lines of Python code, we got our very own analysis tool for URL parameters!
This is what your output file will look like, including the two columns Parameter and Count we defined above and one row for each unique URL parameter, all sorted by their occurrences.
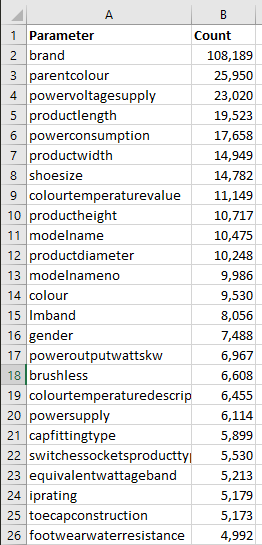
We can then use any software or tools of our choice to further process the tabular data. This will make it easier to make an informed decision on the next steps needed. With some tweaks, you can i.e get this script to also group your parameters into categories:

Thoughts on optimisation
The script took 5 seconds to analyse ~300k URLs on my machine with an i7 CPU. Should you require to process much larger datasets (millions of URLs) I suggest chunking the input list urls into even parts. You can then utilise Python’s multiprocessing capabilities to spawn multiple worker processes to work in parallel on each chunk for the parameter analysis.
Further Reading
If you need any help getting Python set up on your machine, I recommend checking out the installation guide from Real Python, applicable to Windows, Mac and Linux users. For further context around the methods and libraries used, you may also find the following links useful:
Full Script – Ready for Copy & Paste
from pandas import DataFrame, read_csv
import urllib.parse as urlparse
from urllib.parse import parse_qs
input_file = "spreadsheet.csv"
output_file = "output.csv"
url_column = "Address"
urls = read_csv(input_file, usecols=[url_column])[url_column].unique()
parameters = {}
print(f"Analysing {len(urls)} urls ...")
for url in urls:
query_string = urlparse.urlparse(url)
for param in parse_qs(query_string.query):
parameters[param] = parameters.get(param, 0) + 1
parameters = [(key, value) for key, value in sorted(parameters.items(),
key=lambda item: item[1], reverse=True)]
print(f"{len(parameters)} unique URL parameters found.")
print(f"Saving output to {output_file}...")
DataFrame(parameters, columns=["Parameter","Count"]).to_csv(output_file, index=False)At Ayima we focus on Performance, Technology, and Control. We use the perfect blend of talent and tech. If you’re interested in speaking to us about how we can drive granular transparency and meaningful measurement for your business, contact our team here.

